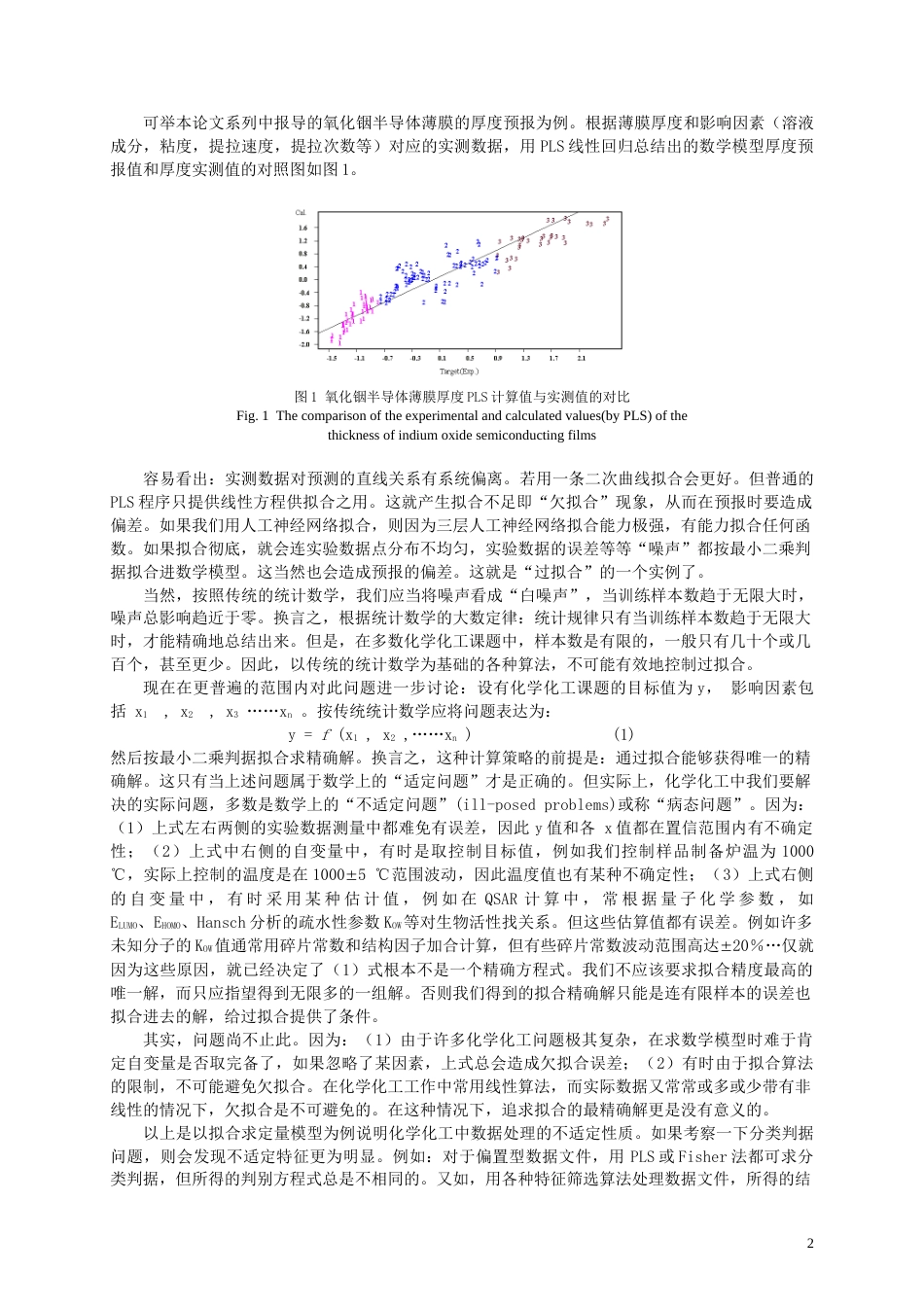
支持向量机及其它核函数算法在化学计量学中的应用陈念贻1,陆文聪1,叶晨洲2,李国正2(1.上海大学化学系计算机化学研究室,上海,200436;2.上海交通大学图象及模式识别研究所,上海,200030)摘要:化学、化工领域中多数数据处理问题属于数学中的“不适定问题”(ill-posedproblem),而传统的化学计量学算法如线性和非线性回归,人工神经网络等忽略了这一特点,将其作为“适定问题”(well-posedproblem)求解。是引发数据处理中“过拟合”问题的重要原因。近年来新提出的“支持向量机算法”适合于处理不适定问题,能限制过拟合,且因采用核函数算法,能有效处理非线性数据集。和当前化学化工中应用极广的人工神经网络相比,优越性明显。在化学化工中具有巨大的应用潜力。关键词:不适定问题;过拟合;支持向量机算法;化学化工中的应用中图分类号:O06-04ApplicationofSupportVectorMachineandKernelFunctioninchemometricsCHENNian-yi1,LUWen-cong1,YEChen-zhou2,LIGuo-zheng2(1.LaboratoryofChemicalDataMining,DepartmentofChemistry,ShanghaiUniversity,Shanghai,200436,China)(2.InstituteofImageandPatternRecognition,JiaotongUniversity,Shanghai,200030,China)Abstract:Inthefieldsofchemistryandchemicalengineering,mostofthedataminingproblemsareactually“ill-posedproblems”.Butthetraditionalmethodsinchemometrics,suchaslinearornonlinearregressionandartificialneuralnetworks,usuallyignoretheill-posedcharacteristicsandtreatthemas“well-posedproblems”.Thisignoranceusuallyinducessignificantoverfittingproblems.Anewlyproposedtechniqueofdatamining,called“supportvectormachine”,issuitableforthedataminingofill-posedproblems,withoutsignificantoverfitting.Besides,sincekernelfunctionisusedinthismethod,itisverysuitableforthedataminingofnonlineardatasets.SincethisnewmethodhassignificantadvantagescomparedwithANN,whichisnowwidelyusedinthefieldsofchemistryandchemicalengineering,supportvectormachineexhibitsgreatpotentialitiesformanyapplicationtopicsinchemistryandchemicalengineering.Keywords:ill-posedproblem;overfitting;supportvectormachine;applicationsinchemistryandchemicalengineering.1许多化学化工中的数据处理问题都是数学上的“不适定问题”(ill-posedproblems),而传统的化学计量学算法将其当作适定问题求解建模,是造成过拟合的重要原因在各种化学,化工的研究和应用工作中,经常要从已知数据中总结规律,用以预报未知。自从计算机技术长足进展以来,应用计算机从已知数据中总结规律,即所谓“机器学习”(machinelearning)的应用已很普遍。除传统的线性回归外,人工神经网络和各种模式识别技术都在广泛使用。并已取得许多成果。当数据的规律接近线性时,用线性回归总结规律,通常认为是标准的、最可靠的方法。如果规律偏离线性,则通常用人工神经网络总结规律,或在线性方程中添加平方或其它高阶项作非线性回归这就是当前化学化工领域中常用的数据处理算法。数据处理,总结数学模型的目的是为了预报未知。但是在实践中,人们经常发现用上述各方法总结的数学模型对已知数据(即所谓训练集)常能拟合较好,而在预报未知样本时,偏差往往较大。当训练样本较少,而影响因素(自变量)较多时,亦即在小样本问题中此问题尤其严重。在数学上将这种现象称为数学模型的“推广能力”(generalizationability)不足的问题。如何提高算法和数学模型的推广能力,以确保我们预报结果的可靠性,显然是化学化工数据处理中非常重要的课题。这其实就是如何避免“过拟合”(overfitting)和“欠拟合”(underfitting)现象的问题。1收稿日期:2002-06-10;修回日期:2002-09-10资金资助:国家自然科学基金委和美国福特公司联合资助,批准号:9716214作者简介:陈念贻(1931-),男,教授,研究方向:计算机化学1可举本论文系列中报导的氧化铟半导体薄膜的厚度预报为例。根据薄膜厚度和影响因素(溶液成分,粘度,提拉速度,提拉次数...