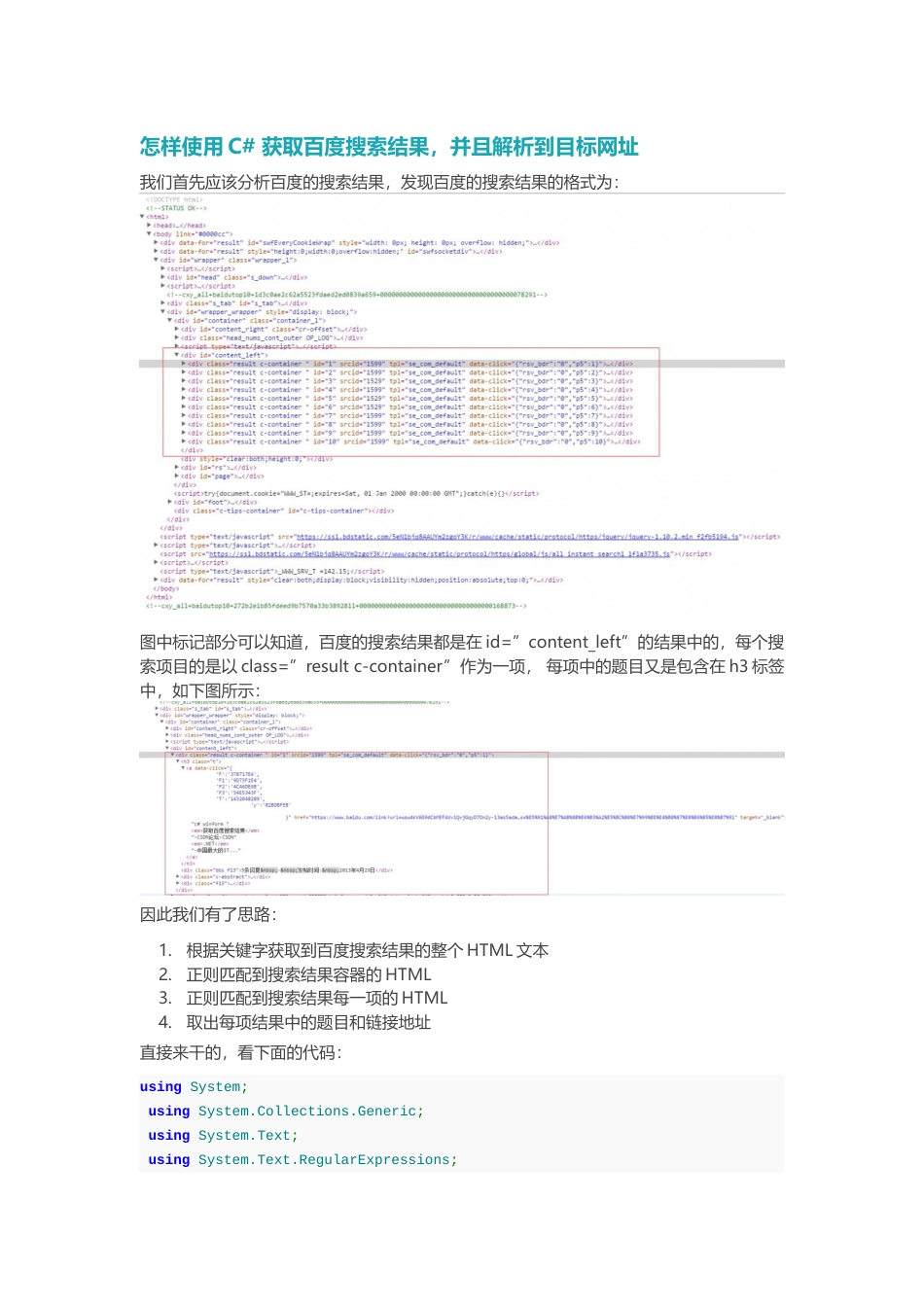
怎样使用C#获取百度搜索结果,并且解析到目标网址我们首先应该分析百度的搜索结果,发现百度的搜索结果的格式为:图中标记部分可以知道,百度的搜索结果都是在id=”content_left”的结果中的,每个搜索项目的是以class=”resultc-container”作为一项,每项中的题目又是包含在h3标签中,如下图所示:因此我们有了思路:1.根据关键字获取到百度搜索结果的整个HTML文本2.正则匹配到搜索结果容器的HTML3.正则匹配到搜索结果每一项的HTML4.取出每项结果中的题目和链接地址直接来干的,看下面的代码:usingSystem;usingSystem.Collections.Generic;usingSystem.Text;usingSystem.Text.RegularExpressions;usingSystem.Web;usingSystem.Net;usingSystem.IO;namespaceBaiduSearchTest{structBaiduEntry{publicstringtitle,brief,link;}classProgram{staticstringGetHtml(stringkeyword){stringurl=@"http://www.baidu.com/";stringencodedKeyword=HttpUtility.UrlEncode(keyword,Encoding.GetEncoding(936));//百度使用codepage936字符编码来作为查询串,果然专注于中文搜索……//更不用说,还很喜欢微软//谷歌能正确识别UTF-8编码和codepage这两种情况,不过本身网页在HTTP头里标明是UTF-8的//估计谷歌也不讨厌微软(以及微软的专有规范)stringquery="s?wd="+encodedKeyword;HttpWebRequestreq;HttpWebResponseresponse;Streamstream;req=(HttpWebRequest)WebRequest.Create(url+query);response=(HttpWebResponse)req.GetResponse();stream=response.GetResponseStream();intcount=0;byte[]buf=newbyte[8192];stringdecodedString=null;StringBuildersb=newStringBuilder();try{Console.WriteLine("正在读取网页{0}的内容……",url+query);do{count=stream.Read(buf,0,buf.Length);if(count>0){decodedString=Encoding.GetEncoding("utf-8").GetString(buf,0,count);sb.Append(decodedString);}}while(count>0);}catch{Console.WriteLine("网络连接失败,请检查网络设置。");}returnsb.ToString();}staticvoidPrintResult(List<BaiduEntry>entries){intcount=0;entries.ForEach(delegate(BaiduEntryentry){Console.WriteLine("找到了百度的第{0}条搜索结果:",count+=1);if(entry.link!=null){Console.WriteLine("找到了一条链接:");Console.WriteLine(entry.link);}if(entry.title!=null){Console.WriteLine("标题为:");Console.WriteLine(entry.title);}if(entry.brief!=null){Console.WriteLine("下面是摘要:");Console.WriteLine(entry.brief);}Program.Cut();});}staticvoidsimpleOutput(){stringhtml="<table><tr><td><font>test</font><a>hello</a><br></td></tr></table>";Console.WriteLine(RemoveSomeTags(html));}staticstringRemoveVoidTag(stringhtml){string[]filter={"<br>"};foreach(stringtaginfilter){html=html.Replace(tag,"");}returnhtml;}staticstringReleaseXmlTags(stringhtml){string[]filter={"<a.*?>","</a>","<em>","</em>","<b>","</b>","<font.*?>","</font>"};foreach(stringtaginfilter){html=Regex.Replace(html,tag,"");}returnhtml;}staticstringRemoveSomeTags(stringhtml){html=RemoveVoidTag(html);html=ReleaseXmlTags(html);returnhtml;}staticvoidCut(){Console.WriteLine("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~");}staticvoidMainProc(stringinput){MainProc(input,false);}staticvoidMainProc(stringinput,booltagsForBrief){Regexr=newRegex(@"<h3[\s\S]*?</h3>",RegexOptions.IgnoreCase);MatchCollectionmatchCollection=r.Matches(input);List<string>collection=newList<string>();foreach(MatchminmatchCollection){stringtextReg=@"<a\s*[^>]*>([\s\S]+?)</a>";MatchCollectiontextMatchCollection=Regex.Matches(m.Value,textReg,RegexOptions.IgnoreCase);foreach(MatchmatchintextMatchCollection){if(match.Success)Console.Write(match.Result("$1"));}stringLinkReg=@"http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?";MatchColl...